The DNA Network |
| Eat your heart out, Weekly World News [genomeboy.com] Posted: 17 Aug 2008 01:40 PM CDT
From the Department of You Can’t Make This Stuff Up:
One wonders if the Raelians were involved. |
| Learning from RedMonk’s “open source” conundrum [business|bytes|genes|molecules] Posted: 17 Aug 2008 01:11 PM CDT Just chanced upon a wonderful post by Steve O’Grady of Redmonk. The post touches upon a subject near and dear to my heart and to those of many in the online bio community; licensing. The background: RedMonk bills itself as an open source analyst firm, and has historically licensed content under a CC-NC-SA license. Well someone pointed out that the NC part of the license goes against the open source ethos. Hmmm, we have a problem here. The solution: Dynamic licensing. The folks at RedMonk are now using a plugin changes the licensing as a function of time. When content is made available, it is available under a CC-NC-SA license, but after 60 days, automatically switches over to a CC-BY-SA license. Now I am not saying we should specifically be using the licenses described here. The key is the problem, which is much the same that many content producers in the life sciences face today. The second key is the action. RedMonk had a problem and found a solution. A few people have said lately that we should stop talking and take action. We have journals that use CC licensing. We have wikis that do the same and many blogs. Science should be fundamentally open source. We have established that many kinds of raw data belong in the public domain, but there is a lot of generated information that belongs to the content producer. I think we have a blueprint here we should think about. ![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=9789ddb5-82e9-429c-bb72-fe7a179d7acb) |
| The data conundrum? [business|bytes|genes|molecules] Posted: 17 Aug 2008 12:40 PM CDT
It is undeniable that we are blessed (or is that suffering) with hitherto unseen amounts of data. It is also true that our currently search and information retrieval technologies, at least those commonly available only scratch the surface of how we can leverage all this information. But the current trend among some pundits to think that this is somehow making us more shallow is disconcerting. In Anderson’s case, the idea that we can somehow discover everything through statistical correlations in a way is also a similar assertion, that through brute force statistics and correlation we will be able to make scientific discoveries, not though insight and intelligence The authors fail to realize that for the majority of us, the non-specialists, the web is a treasure trove of knowledge that most either did not have access to before, or had to do too much work to get. Any knowledge that they have is better than what they would have had in the absence of all this information at our fingertips. Could the tools they have to become more efficient and deal with this information glut be improved? Of course, and so will our habits evolve as we learn to deal with information overload. To some extent any perceived shallowness is a function of our culture, which seems to eschew knowledge, but perhaps that opinion is a function of my own thinking and might also fall into the same category of thinking that Carr and Anderson have displayed. So what about those who make information their life. Creating it, parsing it, trying to glean additional information to it. As one of those, and having met and known many others, all I can say is that to say that the internet and all this information has made us shallower in our searching is completely off the mark. It’s easy enough to go from A –> B, but the fun part is going from A –> B –> C –> D or even A –> B –> C –> H, which is the fun part of online discovery. I would argue that in looking for citations we can now find citations of increased relevance, rather than rehashing ones that others do, and that’s only part of the story. We have the ability to discovery links through our online networks. It’s up to the user tho bring some diversity into those networks, and I would wager most of us do that. So in a nutshell, alarmist articles like Carr’s, or ones that overemphasize data availability like Anderson’s need to be put into context. We are at the infancy of the data glut, about online information availability changing fundamental information discovery behaviour. In the general sense, we need to take advantage of what’s available to us to foster interest and curiosity in kids and casual observers and allowing those who are really interested in drilling down and information discovery to do so. Many of us have already figured out how to be more effective in this era than we ever were before. Addendum: How much do you trust an article on the Britannica blog? IMO, there is a serious credibility issue there Related articles by Zemanta![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=97d9dcb9-9669-4e27-b36b-cb297c42336c) |
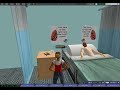
| Unique Medical Simulation in Second Life! [ScienceRoll] Posted: 17 Aug 2008 03:50 AM CDT We organize medical exercises and meetings at the Ann Myers Medical Center in Second Life. Now the e-Learning Faculty of Imperial College London created a spectacular and useful Second Life tool in medical education. Here are some screenshots that can describe what the learning process looks like.
To sum it up, this is an extremely useful application for medical students who would like to learn and study without borders. A video may describe it better:
Further reading:
        |
| OutWit Hub: A Semantic Browser in Medicine? [ScienceRoll] Posted: 17 Aug 2008 02:10 AM CDT OutWit Hub, currently in beta, might be a step towards a semantic browser. You can find more information here and the Firefox Add-on page here.
Here is a tutorial:         |
| Metabolomics Webinar [ScienceRoll] Posted: 17 Aug 2008 01:51 AM CDT There will be a promising webinar focusing on metabolomics organized by Genetic Engineering & Biotechnology News on the 28th of August. You can register here.
Metabolomics: Analytics, Tools, and Applications (August 28, 2008; 1:00 pm EDT; 19:00 CEST)
        |
| Sexy Worms, an E-Tongue, and Kita Running [Sciencebase Science Blog] Posted: 14 Aug 2008 07:00 AM CDT
Stay young and beautiful - NMR spectroscopy has been used uncovered the secret of eternal youth and the ability to attract sexual partners almost at whim. The results suggest it all hinges on a novel group of pheromones. Unfortunately, before you head for the local pharmacy to stock up, these are pheromones of the lab-technician’s favourite worm, the nematode Caenorhabditis elegans, so they are likely to have no effect whatsoever on human behaviour or longevity. Electronic wine tasting - The wine buff’s palate is a complicated multisensory organ as anyone who knows their Bordeaux from their Beaujolais knows. Now, researchers have taken a step towards an artificial nose based on a system amenable to multivariate analysis. The system integrates a multisensor to test wine and grape juice samples for adulteration or vintage fraud. The Kita runners - Protein folding is one of the great conundrums of the twenty-first century. How exactly does a linear string of amino acids “know” into what three-dimensional cross-linked structure to fold itself? Moreover, how might molecular biologists predict this folding from first principles and how might the misfolding seen in prionic diseases, Alzheimer’s and other disorders be prevented or even reversed? A new clue about the folding of proteins comes from studies with a novel technique known as kinetic terahertz absorption spectroscopy (KITA). Green and peasant landscape - There’s also a bonus item on science in art. Post-impressionist artist was rich beyond his wildest dreams but only posthumously. He may have chopped off part of one ear, but he had double vision. At least that’s the idea that emerges from new X-ray studies of one his more mundane paintings - Patch of Grass - which reveals a portrait of a peasant woman beneath. a Sexy Worms, an E-Tongue, and Kita Running |











| You are subscribed to email updates from The DNA Network To stop receiving these emails, you may unsubscribe now. | Email Delivery powered by FeedBurner |
Inbox too full?  Subscribe to the feed version of The DNA Network in a feed reader. Subscribe to the feed version of The DNA Network in a feed reader. | |
| If you prefer to unsubscribe via postal mail, write to: The DNA Network, c/o FeedBurner, 20 W Kinzie, 9th Floor, Chicago IL USA 60610 | |
No comments:
Post a Comment