Spliced feed for Security Bloggers Network |
| SecuraByte Episode 4 [SecuraBit] Posted: 25 Oct 2008 12:43 AM CDT This evening we had a podcast about the new Zero Day Exploit. This exploit covers all versions of windows from 2000 and above. Securabit brought in Tim Krabec from the smbminute.com podcast. This covers the article from Microsoft MS08-067. Hosts: Chris Mills - ChrisAM Chris Gerling - Hak5Chris Anthony Gartner - AnthonyGartner.com Guests: Tim Krabec (Cray Beck) Important links for the show [...] This posting includes an audio/video/photo media file: Download Now |
| Grecs’s Infosec Ramblings for 2008-10-24 [NovaInfosecPortal.com] Posted: 24 Oct 2008 11:59 PM CDT
|
| Microsoft Emergency Security Fix [The IT Security Guy] Posted: 24 Oct 2008 10:26 PM CDT This is something we haven't heard about for a while and that came out of the blue. It's a vulnerability in a bunch of Windows systems that can be remotely exploited with a specially crafted RPC call. What scared security researchers is that this could be exploited in a type of attack like the old Blaster worm of a few years back. These types of worms have been out of fashion lately as hackers have been targeting banking and e-commerce sites with phishing and other more targeted attacks. This one even hit CERT. The original Microsoft bulletin for MS08-067 was followed with more details by posts on its MSRC and SVRD blogs. The Windows versions affected are Windows 2000, Windows XP, Windows 2003 and, to a lesser extent, Windows Server 2008 and Windows Vista, according to Security Focus. This one also made the rounds on the web sites of Symantec and Websense. |
| Sandboxes and Surfing with Google Chrome [Security Provoked] Posted: 24 Oct 2008 03:46 PM CDT Google designed Chrome to be faster, more stable and most importantly, more secure than other Web browsers. So with these features in mind, Google Chrome was built from scratch to be a Web browser designed for today's web application users. As more businesses venture into the cloud, it's becoming increasingly important that your browser doesn't crash when you're creating reports in Google Docs or when you're video conferencing. In order to prevent crashes, Google Chrome developers sandboxed each tab, so that if one tab malfunctions, the whole browser doesn't crash. If one tab does go down, a "sad tab" will appear depicting a 'sad face' emoticon. This isolation process is similar to modern operating systems. With sandboxing, the goal is to prevent malware from installing itself on the computer or allowing what happens in one tab to affect what happens in another. The perimeter of the sandbox is based on permissions. Each process is stripped of its rights and can compute but can't write files or read from sensitive areas such as the desktop or documents. Chrome has taken the existing process boundary and made it into a metaphorical jail. Malicious software in one tab is unable to sniff credit card numbers, interact with mouse operations or tell Windows to run an executable start-up. Since Google is writing the code, they have the ability to say who and who isn't granted permission. If sandboxed tabs don't offer enough security for your end users, there are also privacy modes to ensure that your surfing history isn't being tracked, such as Protected mode used in IE7 and Windows Vista, which can be enabled or disabled by group policy or parental controls. (Apple's Safari also has a private browsing feature). Google Chrome offers a similar mode called Incognito. (Chrome currently cannot disable through parental controls or group policy). These modes are jokingly referred to as 'porn mode' as the Web surfing activity isn't tracked because the browser does not store history information or cookies. A spouse that doesn’t want their significant other to know that he/she has been surfing disreputable sites would not be found-out while surfing in these modes. These privacy modes also have business-related uses as well. Privacy modes are good to utilize when typing passwords or financial, personal or sensitive information onto a Web site. For more information on secure Web browsing and Web 2.0, read the October Alert: http://gocsi.com/membersonly/showArticle.jhtml?articleID=211600271&catID=14144. |
| StillSecure 4 in the Fast 50 [StillSecure, After All These Years] Posted: 24 Oct 2008 11:23 AM CDT
Last night was another such occasion. For the 2nd time, StillSecure was honored as one of the Deloitte Colorado Technology Fast 50. This annual award is in recognition of revenue growth. StillSecure was actually the 4th highest ranked company in Colorado with revenue growth over 5 years of almost 1400%! I accepted the award and spoke on our behalf. It was very gratifying. Also interesting was that the two companies just above us, Accuvant and MX Logic were also security companies. That made 3 of the top 5 being security companies. That is a statement too, I guess! I thought the best speech was from the CEO of Accuvant who said the key to winning was starting off really small. But seriously, we are very grateful for the award and recognition. I can only take little if any credit for it though. All of the hard working people at StillSecure who passionately ply away every day trying to offer the protection our customers are depending on us to provide deserve all of the credit! Related articles by Zemanta![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=4f699ba8-1086-4fa3-8694-453790f9020b) |
| ChicagoCon - Recession-proofing Your Career [Episteme: Belief. Knowledge. Wisdom] Posted: 24 Oct 2008 11:08 AM CDT So, as I mentioned in this post, I’ll be doing a breakout session next weekend at ChicagoCon. The description on the conference website is: “Information security is one of the most difficult industries to navigate a career in. The industry is new, and the skills are ever-changing. The nature of the industry is that the biggest threats are always in the newest technologies, which means that if you’re not actively running, you’re falling behind. Not to mention that there’s no industry standard for certification, for knowledge, or even for what “security” actually is. It’s confusing at the best of times. And this isn’t the best of times. As the industry gets more complex and the economy tightens, a solid career plan and the skills to pull off that plan are going to become ever more important. Industry veteran and respected career speaker and coach Mike Murray will work with the attendees of ChicagoCon to discuss the fundamental skills needed, and put the audience of this breakout session through exercises that will help clarify that plan, and move forward toward their ultimate career goals.” But I wanted to provide some deeper information for those who might be interested or want to know more. We’re going to talk about:
We’ll also talk about real situations that members of the the audience are having, and I’ll be working with people in the class one-on-one to help them prepare themselves for whatever is going to happen next in their careers. |
| ThreatExpert Blog has an excellent write up on the Gimmiv.A worm [Nicholson Security] Posted: 24 Oct 2008 10:12 AM CDT Yesterday Microsoft release a security patch for a critical vulnerability. It seems a worm has been found exploiting this vulnerability in the wild. If you head over to the ThreatExpert Blog you can find a full write-up on this worm and how it’s using this critical vulnerability to exploit systems.
If you run Snort IDS here is a link to rules that block this vulnerability. Random Posts |
| Could this be David? [StillSecure, After All These Years] Posted: 24 Oct 2008 08:42 AM CDT
Reading an article in the NY Times today and doing a little follow up, I think a young David may have come out from the ranks. Arista Networks appears to have the pedigree and perhaps the technology to be anointed. Andy Bechtolshiem, a midas touch Valley investor, who besides co-founding Sun and Granite Systems, also were early in Google and VMware has left Sun to join Arista. He is rejoined with another legendary valley entrepreneur, David R. Cheriton. The CEO of the company is none other than Jayshree Ullal, former head of Cisco's switch business. The battle ground in the switch business over the next few years will be in the high end 10gig market. According to Arista they have better software, faster hardware and a fraction of the cost of the Cisco gear. You can go to the their website and read the Times article for more details about the advantages of their technology. Of course there are still plenty of pretenders and contenders in the switch market. But Arista has the names and it appears the technology to potentially take the king off the hill. It will be interesting to watch! Related articles by Zemanta
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=ee2a0bca-8197-4f75-b368-757a6ba70eb7) |
| Map IP to BGP AS number python script [Francois Ropert weblog] Posted: 24 Oct 2008 08:28 AM CDT This morning I felt on http://nmap.org/book/nse-scripts-list.html then wrote a tiny tool in python to map IP with an AS number, country, AS peers and subnet. Output example: python ip2asn.py 194.140.247.6 AS Numbers: BGP: 194.140.247.0/24 | Country: GB Origin AS: 41156 SUPINFO-AS SUPINFO - International Institute of Information Technology Peer AS: 8928 12600 Peer AS are Interoute and Telecity Paris. SUPINFO is the school where I got my diploma. Enjoy |
| ISC Podcast Episode Eleven Posted [Random Thoughts from Joel's World] Posted: 23 Oct 2008 09:20 PM CDT Hey everyone, sorry it has taken so long to get around to recording another podcast episode. Travel schedules have been very crazy between us lately. Anyway, enough excuses, here is episode eleven. Thanks for all the emails asking me where it is! :) It helps to remind me.... All the podcasts Just this podcast Podcast through iTunes  Subscribe in a reader Subscribe in a reader |
| CRCError [Random Thoughts from Joel's World] Posted: 23 Oct 2008 09:13 PM CDT Recorded CRCError podcast last night, I've edited some of it, but I thought I would post something about the website on here. Well.. it's down. So wtf right? Well something about the hosting company where the server is hosted is retarded or something, I don't know the whole drama or the issue, but we're working to get the server back up, and then punch the hosting provider in the face. Subscribe in a reader |
| Global Information Security Study [The IT Security Guy] Posted: 23 Oct 2008 04:07 PM CDT An annual information security report by PricewaterhouseCoopers says progress has been made in implementing security technologies, but companies still lack leadership and focus, in general, in their IT security programs. The study, which is global in scope and the sixth conducted annually by PWC, said 10 percent of respondents had trouble answering basic questions about where they stored information assets, while 71 percent admitted they don't have an inventory of such assets, according to SC Magazine. Compliance continues to be a key driver for security budgets and implementation but a checklist mentality continues to be confused with real security. "If there's a security tool out there," respondents tended to have it, CSO reported online. While technology is important, it shouldn't be relied upon solely, and isn't a replacement for geniune leadership of security programs, the study concluded. |
| The Dumbest Prediction I’ve Heard in a While [Episteme: Belief. Knowledge. Wisdom] Posted: 23 Oct 2008 03:55 PM CDT I was reading Hoff’s recent post on virtualization, and I found myself needing to write a bit of a rant. I don’t usually have much to say about what Hoff writes about, because virtualization isn’t an area that I spend any time on. But in Hoff’s critique of Tarry Singh’s latest post, there was something that blew my mind. Tarry asserts in his post that one of the good things about hackers spending time finding vulnerabilities is that (and I quote): “Security and Compliance will be core focus of all organizations (as regulators will come knocking at your doorsteps)” Umm… I hate to say it, but that ain’t ever gonna happen. No matter how many regulators show up on someone’s doorstep, that counts as one of the least well-thought-out predictions I’ve ever heard. Simply put:
If those organizations ever make “Security and Compliance” their core focus, they won’t have businesses anymore. While we may think that security is important, the day that it surpasses the core focus of any business (that isn’t in the security and compliance business) is the day that that business has taken their eye off the ball. By definition. |
| Posted: 23 Oct 2008 03:51 PM CDT The third in the series where I am trying to think through the current approaches to securing virtual environments... See part one and two here... Virtualization enables organizations to optimally manage their infrastructure resources. It can provide significant cost benefits (by sharing resources), flexibility (by just-in-time allocation of resources where they are needed), and agility (speed of provisioning resources). Therefore, organizations have been able to virtualize:
This makes data the "constant" in a dynamically changing environment — even if the location of data itself is virtualized. Data will also have the longest lifetime of the four elements in the infrastructure and thus will have to live "outside" of the virtual environment. Therefore, from a security standpoint, it is imperative that data becomes the focus of protection - and we dont just continue protecting the infrastructure. Data is the critical asset, and since it travels across boundaries and lives longer than virtual elements, it can be easily compromised. |
| Microsoft MS08-067 [Security Balance] Posted: 23 Oct 2008 03:18 PM CDT I have been away from the blog for a while because of a series of reasons, but I couldn’t avoid to comment on this recently published advisory from Microsoft, MS08-067. Just as some worms we witnessed in the past, this one is related to a core Windows service, meaning that almost all boxes are vulnerable. It’s also interesting to see that the security efforts related to Vista and Server 2008 had brought results as those versions are not as vulnerable as previous versions to this issue. Thanks to DEP and ASLR for that! Now it’s just a matter of time for the first worms and bots. I’m already seeing some emergency patch management processes being fired to deal with that, but it’s important to ensure that detection and reaction capabilities are also up-to-date. Keep an eye on the sources for IDS signatures and be sure to check if your SIEM/Log analysis systems are able to identify abnormal traffic related to the Server service (139/445 TCP). Do a quick review of your incident management procedures to ensure that people will know what to do if the bell rings. For instance, if you catch signs of infection in your internal network, how will you act to identify and clean the infected computers? May the Force be with you! |
| MindshaRE: Path Finding [DVLabs: Blogs] Posted: 23 Oct 2008 01:39 PM CDT Posted by Cody Pierce How many times have you been at an address in IDA and wanted to know all the ways you could reach that point? A million? Probably not. But its pretty useful to be able to find all the paths leading to a particular location in a binary. That's why today we are going to cover path finding. MindshaRE is our weekly look at some simple reverse engineering tips and tricks. The goal is to keep things small and discuss every day aspects of reversing. You can view previous entries here by going through our blog history. Path finding is a term we use at TippingPoint to describe a way to get from point A to point B in a binary. Aaron and Cameron discussed this subject a little at ToorCon Seattle 2008. Their slides can be found here. Let's break the process of path finding down into its components and provide some automation for your use. When trying to find a path you must first get all cross references from point B. If point A occurs in one of those cross references we can pull out that list of cross references for further inspection. Most of the time this works, however keep in mind that indirect calls will not be discovered using merely cross references. For that I believe a combination of static and live analysis may be needed. Once we locate point A in the cross references of point B we must walk down each basic block looking for the path to point B that showed up in the cross references. To achieve this we will use IDAPython to check one instruction at a time for a branch to the next function in the path we made note of while walking the cross references. Lets take a look at the following example. We have located a function in calc.exe that we want a path to. .text:01011F1D _mulnumx proc nearNow we want to see how to get to _mulnumx from a function higher up. .text:0101239E numpowlongx proc nearSo we want to know how to get from numpowlongx to _mulnumx. Lets look at numpowlongx: .text:0101239E numpowlongx proc near .text:0101239E .text:0101239E var_4 = dword ptr -4 .text:0101239E arg_0 = dword ptr 8 .text:0101239E arg_4 = dword ptr 0Ch .text:0101239E .text:0101239E push ebp .text:0101239F mov ebp, esp .text:010123A1 push ecx ... .text:010123BB loc_10123BB: .text:010123BB test bl, 1 .text:010123BE jz short loc_10123CB .text:010123C0 push dword ptr [esi] .text:010123C2 lea eax, [ebp+var_4] .text:010123C5 push eax .text:010123C6 call mulnumx ...A little common sense tells us that following mulnumx well most likely get us to _mulnumx: .text:01012314 mulnumx proc near .text:01012314 .text:01012314 arg_0 = dword ptr 8 .text:01012314 arg_4 = dword ptr 0Ch .text:01012314 .text:01012314 push ebp .text:01012315 mov ebp, esp ... .text:01012390 loc_1012390: .text:01012390 push esi .text:01012391 push ebx .text:01012392 call _mulnumx ...This particular example is easy, but lets write a script to do these steps for us. It will allow us to find a path quickly. If you remember a while back we used a script called get_recursive_xrefs.py to find all xrefs to point B. Lets add a function to the Node class in that script to search for a particular function in the cross references. def path(self, name, path=None): if path == None: path = [] path.append(self.name) if name == self.name: return True for c in self.children: if c.path(name, path): return path else: path.pop() return FalseNow we just need some points to find. pointa = 0x0101239E pointb = 0x01011F1D pointa_name = GetFunctionName(pointa) pointb_name = GetFunctionName(pointb)
t = get_xref_args(pointb) path = t.path(pointa_name) print pathThe output gives us something like so: [*] Looking for the path from numpowlongx to _mulnumx ['_mulnumx', 'mulnumx', 'numpowlongx']So the call chain is numpowlongx -> mulnumx -> _mulnumx. Alone, this can be very helpful if you want to find your way in smaller functions, or just want some hints. The point of path finding however is to find the specific locations the code executes to get from point A to point B. If we fix up this script a little bit we can get closer. Now we want to walk each function in this list, and look for calls to the subsequent function in the path. def find_branch(source, dest): source_ea = get_function_by_name(source) if not source_ea: return False source_start, source_end = get_function_limits(source_ea) curea = source_start for curea in Heads(source_start, source_end): mnem = GetMnem(curea) if 'call' in mnem: location = GetOpnd(curea, 0) if location == dest: print "%s:%x" % (source, curea) Putting this together with our previous changes delivers the following results. [*] Looking for the path from numpowlongx to _mulnumx ['_mulnumx', 'mulnumx', 'numpowlongx'] [*] Need to find the branch from numpowlongx to mulnumx numpowlongx:10123c6 numpowlongx:10123ce [*] Need to find the branch from mulnumx to _mulnumx mulnumx:1012392The output is telling us that at address 0x10123c6 in function numpowlongx a call to mulnumx is made. We can corroborate all of these addresses easily. numpowlongx: .text:010123C6 call mulnumx .text:010123CE call mulnumxmulnumx: .text:01012392 call _mulnumxThat helps us a little bit more. We can now get the specific address of each paths call to the next link in the chain. The last big step is making this information even more usable. If we colored all paths to these calls in the current function, we can easily see how the binary gets from point A to B during execution. Any loops, or conditional branches will be easily identified once we color everything. This is the most important step in my opinion. When you want to find a path you want to see every instruction and basic block that can get there. For instance if we want to go from a recv call to a possible vulnerability we want to determine which conditions must be met to get there. After some more changes to our script we can see the path colored in the mulnumx function outlining how to get to _mulnumx.  That is a lot more useful in my opinion. At a glance we know what must be done, and every possible way, to get to _mulnumx. Path finding is an invaluable tactic, especially for tasks such as vulnerability analysis, or exploit development. It takes a lot of the manual work out of tracking down a function by reversing line by line from point A without knowing where point B is. We can take this even futher but color coding conditional branches and their condition check. Imagine being able to quickly tell that the first 4 bytes of a packet must be 0x10203040 to get to a vulnerable function. The script used in this example can be found here get_path.py but I must warn you. I have not fully tested it, and there could be bugs. I wrote it as an example for this entry. For a better script take a look at Aaron's code which allows you to find paths, and much more. His code will be released some time in the future as he's currently working on cleaning it up. If you have some additional ideas for path finding please leave a comment. -Cody |
| DNS based GSLB demystified (part 1/3) [Francois Ropert weblog] Posted: 23 Oct 2008 04:55 AM CDT DNS-based GSLB demystified is a serie of 3 articles wrote by a guest blog author: Surya Arby - Consulting Network Engineer at A&O systems+services who mainly worked in massive and critical deployment projects for french government and big companies. The article will be splitted in 3 parts: Introduction, DNS caching and and persistence. Please post comments if you are interesting in GSLB or want to know what vendors hides you ;-) The first part begins now!
- What is GSLB? GSLB stands for “Global Server Load Balancing” or “Global Site Load Balancing”, opposed to Local Server Load Balancing (SLB). Local SLB is the use of a single box (or two if using standard clustering of network devices) used to load balance connections to a specific server farm, usually located in the same datacenter (it is possible to use extended clusters over Layer 2 but this is out of the scope of this article). Multiple implementations of GSLB exist: HTTP Redirect, Route Health Injection (RHI) and DNS. DNS is defined in RFC 1034 and 1035. In this article, the DNS-based solution will be studied now because this one is widely deployed. Some basic DNS-based GSLB can be achieved with BIND and scripts used for servers health checks. Proprietary solutions (Cisco, Citrix, F5, Foundry, Radware, Nortel…) are available with advanced features like site persistence, advanced load balancing methods…
- The need for GSLB Having a service disruption in a datacenter may lead to a lot of money being lost, so a lot of companies want “business continuity”, if a disaster strikes in a white room, all people should work like if nothing would have happened. GSLB is used for load sharing over multiple sites (active/active), and disaster recovery (active / standby). Another technique can be used, based on “proximity”, sending the user to the closest datacenter (”close” definition will be explained later). The big picture:
- The GSLB Core: DNS resolution process In our example, an application is hosted in two datacenters, one located in Paris (IP: 1.1.1.1) and the second in Los Angeles (IP: 2.2.2.2). The client uses an FQDN in his Web browser: www.domain.com and the browser send a DNS request. The resolver performs the iterative resolution:
In the end, The GSLB device acts as authoritative name server for the name www.domain.com. When the GSLB device receives the request, it polls all available datacenters, select one of them (the “best” according to the chosen method) and sends it’s IP address back to the resolver, which sends the DNS response back to the user. Then the user goes to the selected datacenter.
The main advantage of a DNS-based solution is that it requires minimal changes in the IP / DNS infrastructure. It is protocol independent, gives a high level of granularity (names) and permits on the fly configuration modifications. Go to DNS based GSLB demystified Part 2 (link in a few days) |
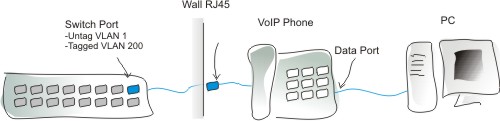
| Securing Multiple Device Auth on 802.1X [Security Uncorked] Posted: 22 Oct 2008 10:15 PM CDT Part II of the Clearing Up 802.1X Series VLANs and Multiple Device Authentication When implementing multiple device authentication on a single port with 802.1X, there are *lots* of considerations, but one major one I see from a security perspective. I’m giving an example of issues and best practices with multiple device authentication using a VoIP scenario because it’s the most common use of multi auth, and probably the single largest vulnerability point because of accessibility to phones in an organization. A VoIP Example
*click image to enlarge If you’re reading this blog, you should immediately know what this means. If not, I’ll try to talk it through. In enterprise environments with VoIP, we use a protocol called LLDP-MED and/or DHCP scopes to tell VoIP phones where they should be on the network, and let the infrastructure identify them as phones. So, a phone will hop on the network, get it’s DHCP information and then be told to go to it’s Voice VLAN (let’s say VLAN 200 is Voice). During this process, the phone is actually communicating initially on the default Data VLAN (let’s say VLAN 1) to get the scope information. In this configuration, the Switch Port (shown above) will be untagged for the Data VLAN 1 and tagged for the Voice VLAN 200, to allow the phone and PC to access the data network and then the phone to access it’s Voice network. The Issue On most switches, when it does this, it leaves VLAN 1 ‘open’ and authenticated. So, it would be easy for a malicious user or guest to easily access our data VLAN from anywhere they can find a phone, even though we have port security turned on. The Resolution 1. One resolution is to create a trash or ‘black hole’ VLAN as I call it. This would be a VLAN to nowhere… and that would be the configured default untagged VLAN on the switch ports (either all of them, or the ones exposed to this environment). If you go this route, there are a couple of things to address- you’ll need to create a path for your phones to be able to access their DHCP server so they can receive scope info and get on the appropriate VLAN to operate. You also have to think about your migration path from an unauthenticated to authenticated network. Generally we recommend customers moving to 1X to use null VLAN assignments to activate whatever current VLAN is untagged on the port (to accommodate current network design). If the port is untagged for a black hole VLAN, you’ll need to actually push ‘real’ authenticated VLAN assignments down (from RADIUS or your NAC solution) for every user. 2. A Second idea would be to use either the guest VLAN or a quarantine VLAN as the default untagged VLAN on the edge ports. This would give some immediate but limited connectivity. Again here, we have a few issues. Currently, most switches do not support unauthenticated devices and authenticated devices on the same port, meaning the guests would have to be *somehow* authenticated- perhaps with Web-auth on a true Guest VLAN (versus the 1X-specified ‘unauth’ VLAN). (There are also some tricky things you can do with a good RADIUS server to get around this.) If you think this sounds a little confusing- you’re right. There are lots of terms in 1X that may ’seem’ to intuitively mean one thing but have a very specific meaning within the confines of 1X. The unauth-VLAN is one of those terms. And, of course, with a quarantine or guest VLAN we have the same requirement to allow the phones access to resources they may need. The Conclusion The Future # # # |
| The Real Scoop on Multiple Device Auth with 802.1X [Security Uncorked] Posted: 22 Oct 2008 10:12 PM CDT Part I of the Clearing Up 802.1X Series Pure vs Applied 802.1X When I talk about 802.1X with people, I like to distinguish ‘pure’ 802.1X with ‘applied’ 802.1X- meaning, there is both the 802.1X that is a strict formalized standard, and then there is the reality of 802.1X and related standards that mix the ‘pure’ 1X with vendor interpretations and extensions. Below are some examples of use-cases of 802.1X that may operate outside the scope of the 1X current standards. Applied 802.1X use cases…
Multiple Device Auth with 802.1X-Now But let’s say that (as in most organizations) not every device supports 802.1X, so we end up with VoIP phones that are not 1X-capable, and we’re using MAC-Auth for those, with 802.1X for the PCs connected through them… different story. Mixed Authentication I would say this would change, but with the expectations of 802.1X-REV coming early next year, vendors and IEEE may decide not to put more effort into a superseded technology. (I think there may be some interest in continuing development and support of 802.1X-2004 since the revision will require a hardware refresh to make use of MACSec/802.1AE). :::Glossary:::
:::Links:::
:::Next::: # # # |
| Clearing Up 802.1X [Security Uncorked] Posted: 22 Oct 2008 09:37 PM CDT After much poking and prodding from various colleagues and customers, I’m finally hopping back on the blog train. By this point everyone seems to refer to me as ‘The 1X geek’, probably because of my evangelical technical overviews and implementations of the standard. I s’pose because of this, in the past week several folks have asked me to check out recent articles by Mike Fratto (New Protocols Secure Layer 2, October 4) and follow up blog by Richard at Tao Security (Hop by Hop Encryption: Needed?) about 802.1X and the upcoming revision of the standard due in 2009. I can tell you Mike always does his homework, and those of us interested in 1X get our technical details straight from the horse’s mouth, so to speak. Mike is no exception and I’m always comfortable referring readers to his blogs and articles for information. To answer the questions I’ve received, I’ve put together a few bite-sized snippits of information on both the current 802.1X standard, its use with multiple device auth, its use with mixed authentication and the upcoming 802.1X-REV… The Clearing Up 802.1X Series Begins…
# # # |




{kind=link}
| You are subscribed to email updates from Security Bloggers Network To stop receiving these emails, you may unsubscribe now. | Email Delivery powered by FeedBurner |
| Inbox too full? Subscribe to the feed version of Security Bloggers Network in a feed reader. | |
| If you prefer to unsubscribe via postal mail, write to: Security Bloggers Network, c/o FeedBurner, 20 W Kinzie, 9th Floor, Chicago IL USA 60610 | |
No comments:
Post a Comment