The DNA Network |
| Maybe I’m not crazy after all… [Mailund on the Internet] Posted: 21 Sep 2008 02:42 PM CDT This evening I was reading in Pattern Recognition and Machine Learning, the book we use in our machine learning class. We only use the first half of the book, but we are thinking about extending the class to cover two terms and then cover the entire book (or most of it, anyway) so I figured this was a good excuse to actually read the whole book. So far, I’ve only read the chapters we actually use, plus a few pages here and there. Anyway, I was reading chapter 6, on kernel methods, but I got stuck on the first figure. It is supposed to illustrate kernel functions k(x,x’) as linear combinations of feature functions: k(x,x’)=Σφi(x)φi(x’). The top row shows the feature functions, φi(x), and the bottom row the kernel function, as a function of x with x’ fixed at 0. That doesn’t make any sense at all to me. On the left-most figure, the feature functions are all 0 for x’=0, so the kernel function is a sum of zeroes. It should be constant zero, not the curvy blue line. For the other two, the feature functions are all non-negative, so how can the kernel function ever be negative? A product of non-negative values cannot be negative, and neither can the sum of non-negative numbers. In short, the figure is all wrong. There isn’t a single thing right about it. That was my reasoning, in any case, but I wasn’t completely sure. I could be missing something. So I googled for the book, but then I found powerpoint presentations including the figure, with no mentioning of any errors. Clearly someone was using the figure in their teaching, so maybe it wasn’t wrong after all. It got me nervous. I feel that I really need to understand something to teach it, so I expect other people to feel the same way, and someone had used this figure. I am not mentioning names here, ’cause as you have probably guessed the figure is wrong. There is nothing wrong with my reasoning above. Well, another minutes Googling found me the errata list, and sure enough, the figure is fixed there.
I’m happy to find that I hadn’t completely misunderstood the topic and that I was right about the figure. I am a little disappointed that a teacher would use the figure without at least checking that the figure actually makes sense. Showing an example that makes no sense at all is doing a lot of harm to the students… |
| Assay Depot launches [business|bytes|genes|molecules] Posted: 21 Sep 2008 01:39 PM CDT Assay Depot, a virtual marketplace that I’ve blogged about before has formally launched AssayDepot.com.  I’ve always like the idea of a company that is completely virtual and acts like a broker between users and providers, allowing you to integrate options and removing some of the pain in the process. That they have a virtual infrastructure and are cool folk only makes it better. The following is an example when you click on a particular service  See the standard Disclaimer ![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=ad997da4-889c-44d6-9893-87a07b81b863) |
| Software development orgs [business|bytes|genes|molecules] Posted: 21 Sep 2008 01:02 PM CDT
As software-development organizations respond to shifting industry trends, they will need to make strategic decisions about which of these types they want to be. Only when an organization understands its strengths and shortcomings can it make the most of its software-development teams. That’s from an article in the McKinsey Quarterly on Where software vendors should focus. The article by itself is somewhat obvious to anyone who’s been involved in the software development busines, or should I say it should be. I have seen too many companies (and I am sticking to the life science space here) try and be something they are not set up to be. Most often, they change direction or strategy, but forget that any such changes often require fundamental changes to the organization, both in terms of personnel and structure and often business model. The McKinsey articles identifies the types of orgs as
Would be interesting to see how some of you define these categories and what kind of orgs do you like working in. I’ve always found myself at home with Innovators, but, and this might be surprising, also enjoyed the challenges of being a Cost Champ, which is a lot harder than it sounds. Related articles by Zemanta![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=de909cd2-89f7-45f9-96b0-47aff8965b6e) |
| Medical Education Evolution: The Database [ScienceRoll] Posted: 21 Sep 2008 11:56 AM CDT Medical Education Evolution is a community for those who are passionate about changing medical education with web 2.0 tools. We are working on a concept about how to implement web 2.0 tools into medical education. That’s why we started to construct a database of medicine 2.0-related links. If you have suggestions how to improve the database, feel free to drop me an e-mail so I can invite you to edit the page.
Ted Eytan, one of the founders, had some comments about it as well. The first medicine 2.0 course at a medical school (University of Debrecen) will start next Thursday (26. 09.) and I will start with defining web 2.0’s role in medicine and healthcare. I hope this class can be an experimental one and we can see whether students like the concept or not.       |
| Posted: 21 Sep 2008 09:15 AM CDT What do you do if you're a scientist and want to volunteer in a classroom? How do you find the right place to go and right kind of activity that suites your talents? One of my commenters asked about this a few weeks ago. With the new school year up and running, it seems like a good time to tackle this question. Read the rest of this post... | Read the comments on this post... |
| Be careful with your types! [Mailund on the Internet] Posted: 21 Sep 2008 08:35 AM CDT I’ve spent the last two hours debugging scripts only to find that the error wasn’t in the scripts but in my analysis of the result… I’m scanning a genome alignment for informative indels (indels where exactly two of four share a gap that starts and stops at the same position). My scripts find the position of each of those and outputs it together with the two species having the gap: HC for human and chimp sharing the gap, HO for human and orangutan sharing the gap, HM for human and macaque sharing the gap, etc. Now, in most of my analysis of this I do not want to distingush between which pair has the gap and which does not, I am only interested in the quartet topology (HC|OM vs. HO|CM for example). So I want to re-map the pairs CM to HO, CO to HM and OM to HC. I do my analysis in R, and this is how I did the re-mapping: data$pair <- factor(sapply(data$pair, switch, HC="HC", HO="HO", HM="HM", CM="HO",CO="HM",OM="HC")) The result is not what you’d expect: > table(data$pair) CM CO HC HM HO OM 705 336 30377 646 349 13089 > data$pair <- factor(sapply(data$pair, + switch, HC="HC", HO="HO", HM="HM", CM="HO",CO="HM",OM="HC")) > table(data$pair) HC HM HO 13794 30726 982 There is clearly something wrong in the mapping. The total number is correct, but HC now is not the sum of the earlier HC and CM! This is how I should have done it: data$pair <- factor(sapply(as.character(data$pair), switch, HC="HC", HO="HO", HM="HM", CM="HO",CO="HM",OM="HC")) Do you notice the difference? The type of data$pair is factor so it is encoded as levels (numbers 1 to 6). The switch function uses these leves as if they were integers, and use them to index into the list HC=”HC”, …, OM=”HC”. If data$pair contained strings then switch would match them against the names in that list, but when it is integers it doesn’t. The type really matters here. > data$pair <- factor(sapply(as.character(data$pair), + switch, HC="HC", HO="HO", HM="HM", CM="HO",CO="HM",OM="HC")) > table(data$pair) HC HM HO 43466 982 1054 |
| What’s on the web? (21 September 2008) [ScienceRoll] Posted: 21 Sep 2008 04:21 AM CDT
      |
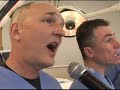
| Breathe: Doctors with Microphone [ScienceRoll] Posted: 21 Sep 2008 03:44 AM CDT No comment:
Ok, just a short note. Their name is The Laryngospasms and have an own website where you can download other songs as well like the Fractured Femur.
(I found it on Gruntdoc who found on Kevin, MD who found it on EverythingHealth)       |







| You are subscribed to email updates from The DNA Network To stop receiving these emails, you may unsubscribe now. | Email Delivery powered by FeedBurner |
Inbox too full?  Subscribe to the feed version of The DNA Network in a feed reader. Subscribe to the feed version of The DNA Network in a feed reader. | |
| If you prefer to unsubscribe via postal mail, write to: The DNA Network, c/o FeedBurner, 20 W Kinzie, 9th Floor, Chicago IL USA 60610 | |
No comments:
Post a Comment